
leveldb-整体架构
前言
项目中使用leveldb做为存储,使用过一段时间后,对leveldb进行一个深入的学习,让录本人学习过程中理解。过程中参照网上文章以经实际应用,进行文章输出,如果错漏,还望指正。
整体架构
leveldb是一个写性能十分优秀的存储引擎,是典型的LSM树(Log Structured-Merge Tree)实现。
LSM树的核心思想就是放弃部分读的性能,换取最大的写入能力。这个很重要,后续深入会发现的leveldb的原理都是基于最大的写入性能去设计的。
LSM树写性能极高的原理,简单地来说就是尽量减少随机写的次数。对于每次写入操作,并不是直接将最新的数据驻留在磁盘中,而是将其拆分成
(1)一次日志文件的顺序写
(2)一次内存中的数据插入。
leveldb正是实践了这种思想,将数据首先更新在内存中,当内存中的数据达到一定的阈值,将这部分数据真正刷新到磁盘文件中,因而获得了极高的写性能(顺序写60MB/s, 随机写45MB/s)。
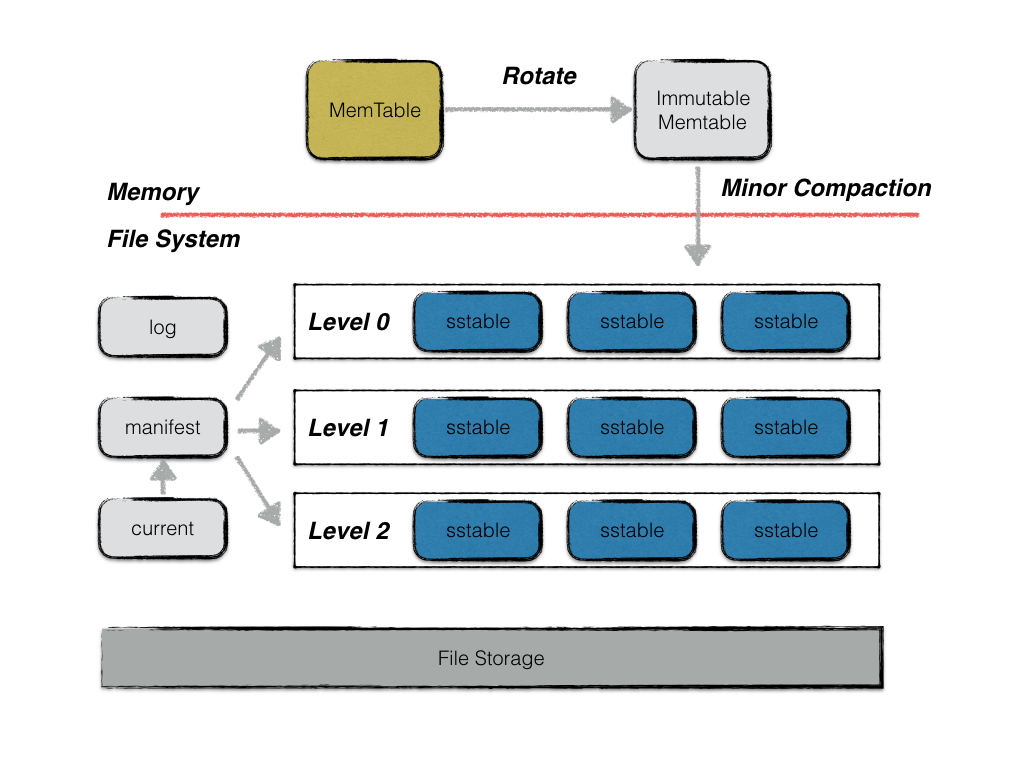
从图里能看出 LevelDB 主要结构包括:
1.内存结构
- MemTable
- Immutable MemTable 不可变内存结构
2.磁盘文件
- Current 文件
- Manifest 文件
- log 文件
- SSTable 文件
Memtable
使用 leveldb,数据先写入内存,最终落入磁盘。
leveldb的一次写入操作并不是直接将数据刷新到磁盘文件,而是首先写入到内存中作为代替,memtable就是一个在内存中进行数据组织与维护的结构。
memtable中,所有的数据按用户定义的排序方法排序之后按序存储,等到其存储内容的容量达到阈值时(默认为4MB),便将其转换成一个不可修改的memtable,与此同时创建一个新的memtable,供用户继续进行读写操作。
memtable底层使用了一种跳表数据结构,这种数据结构效率可以比拟二叉查找树,绝大多数操作的时间复杂度为O(log n)。
Immutable Memtable
memtable的容量到达阈值时,便会转换成一个不可修改的memtable,也称为immutable memtable。
这两者的结构定义完全一样,区别只是immutable memtable是只读的。当一个immutable memtable被创建时,leveldb的后台压缩进程便会将利用其中的内容,创建一个sstable,持久化到磁盘文件中。
所有 KV 数据都是存储在 Memtable,Immutable Memtable 和 SSTable 中的,Immutable Memtable 从结构上讲和 Memtable 是完全一样的,区别仅仅在于其是只读的,不允许写入操作,而 Memtable 则是允许写入和读取的。当 Memtable 写入的数据占用内存到达指定数量,则自动转换为 Immutable Memtable,等待 Dump 到磁盘中,系统会自动生成新的 Memtable 供写操作写入新数据,理解了 Memtable,那么 Immutable Memtable 自然不在话下。
Log 文件
写入内存前先写 log 文件,这个文件是磁盘文件,类似于 MySQL 的 binlog。
leveldb的写操作并不是直接写入磁盘的,而是首先写入到内存。假设写入到内存的数据还未来得及持久化,leveldb进程发生了异常,抑或是宿主机器发生了宕机,会造成用户的写入发生丢失。因此leveldb在写内存之前会首先将所有的写操作写到日志文件中,也就是log文件。当以下异常情况发生时,均可以通过日志文件进行恢复:
- 写log期间进程异常;
- 写log完成,写内存未完成;
- write动作完成(即log、内存写入都完成)后,进程异常;
- Immutable memtable持久化过程中进程异常;
- 其他压缩异常(较为复杂,首先不在这里介绍);
当第一类情况发生时,数据库重启读取log时,发现异常日志数据,抛弃该条日志数据,即视作这次用户写入失败,保障了数据库的一致性;
当第二类,第三类,第四类情况发生了,均可以通过redo日志文件中记录的写入操作完成数据库的恢复。
每次日志的写操作都是一次顺序写,因此写效率高,整体写入性能较好。
此外,leveldb的用户写操作的原子性同样通过日志来实现。
SSTable (Sorted String Table)
这个是数据存储的文件。
虽然leveldb采用了先写内存的方式来提高写入效率,但是内存中数据不可能无限增长,且日志中记录的写入操作过多,会导致异常发生时,恢复时间过长。因此内存中的数据达到一定容量,就需要将数据持久化到磁盘中。除了某些元数据文件,leveldb的数据主要都是通过sstable来进行存储。
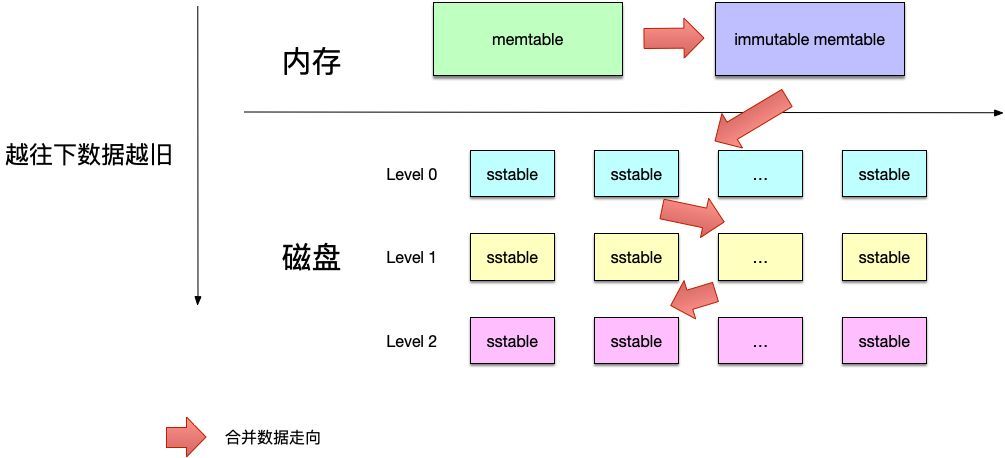
虽然在内存中,所有的数据都是按序排列的,但是当多个memetable数据持久化到磁盘后,对应的不同的sstable之间是存在交集的,在读操作时,需要对所有的sstable文件进行遍历,严重影响了读取效率。因此leveldb后台会“定期“整合这些sstable文件,该过程也称为compaction。随着compaction的进行,sstable文件在逻辑上被分成若干层,由内存数据直接dump出来的文件称为level 0层文件,后期整合而成的文件为level i 层文件,这也是leveldb这个名字的由来。
注意,所有的sstable文件本身的内容是不可修改的,这种设计哲学为leveldb带来了许多优势,简化了很多设计。具体将在接下来的文章中具体解释。
看下sst的整体结构
注意,sst 是逻辑上的结构,实际物理文件会有序号进行排序,但并不代表其层级。
manifest 文件
leveldb中有个版本的概念,一个版本中主要记录了每一层中所有文件的元数据,元数据包括
(1)文件大小
(2)最大key值
(3)最小key值
该版本信息十分关键,除了在查找数据时,利用维护的每个文件的最大/小key值来加快查找,还在其中维护了一些进行compaction的统计值,来控制compaction的进行。
SSTable 中的某个文件属于特定层级,而且其存储的记录是 key 有序的,那么必然有文件中的最小 key 和最大 key,这是非常重要的信息,LevelDB 应该记下这些信息。manifest 就是干这个的,它记载了 SSTable 各个文件的管理信息,比如属于哪个 level,文件名称叫啥,最小 key 和最大 key 各自是多少。

图中只显示了两个文件(manifest 会记载所有 SSTable 文件的这些信息),即 level 0 的 Test1.sst 和 Test2.sst 文件,同时记载了这些文件各自对应的 key 范围,比如 Test1.sst 的 key 范围是 “abc” 到 “hello”,而文件 Test2.sst 的 key 范围是 “bbc” 到 “world”,可以看出两者的 key 范围是有重叠的。
current 文件
这个文件的内容只有一个信息,就是记载当前的 manifest 文件名。因为在 LevleDB 的运行过程中,随着 compaction 的进行,SSTable 文件会发生变化,会有新的文件产生,老的文件被废弃,manifest 也会跟着反映这种变化,此时往往会新生成 manifest 文件来记载这种变化,而 current 则用来指出哪个 manifest 文件才是我们关心的那个 manifest 文件。
注意,每次leveldb启动时,也都会创建一个新的Manifest文件。





