前言 TRON 的数据还原点checkpoint指的是数据在某一刻建立的一个快照的备份,给内存快照(snapshot)生成一个临时持久化存储。
作用 保存数据在内存中的状态到碰盘,用于服务异常数据异常恢复 。临时写入到磁盘当中,当处理成功后删除本次的checkpoint,待下一次刷盘时,重新创建checkpoint,重复这个过程。
在此之前需要对TRON的内存快照机制有一定的了解。
刷盘机制 TRON中的刷盘和很多别的应用的刷盘一样,都是将内存中的数据刷入到磁盘当中。也就是说:TRON对数据的写入是先内存,后磁盘。
A 给 B 转10块钱,这笔交易需要等待刷盘时机触发,才会写入到内存当中
为了解决这一问题的,使用 checkpoint 机制。
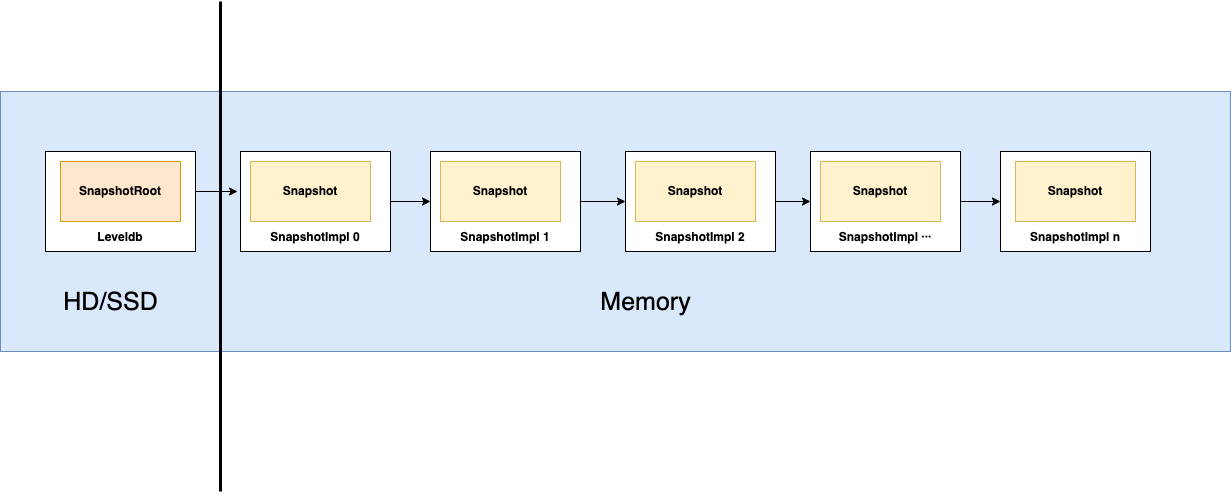
先看一下内存中的数据结构图,每一次对区块操作,都会创建一个对应区块的checkpoint。SnapshotRoot是对leveldb的抽象,并不是一个内存的snapshot,而SnapshotImpl是对应每一次操作生成的一个内存快照,数据存储在ConcurrentHashMap。
checkpoint 机制 在写入磁盘之前,先写入一个临时存储,这个临时存储就是一个checkpoint。功能。
机制 主要做三件事,这三件事也是checkpoint的逻辑顺序:
检查checkpoint
删除checkpoint
创建checkpoint
启动服务时检查checkpoint,在刷盘之前检查上一次是否存checkpoint并删除checkpoint,最后创建checkpoint,用于防止服务异常挂了后造成的数据库异常。
实现 看一下主要的处理逻辑:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 public void flush () if (unChecked) { return ; } if (shouldBeRefreshed()) { try { long start = System.currentTimeMillis(); deleteCheckpoint(); createCheckpoint(); long checkPointEnd = System.currentTimeMillis(); refresh(); flushCount = 0 ; logger.info("flush cost:{}, create checkpoint cost:{}, refresh cost:{}" , System.currentTimeMillis() - start, checkPointEnd - start, System.currentTimeMillis() - checkPointEnd ); } catch (TronDBException e) { logger.error(" Find fatal error , program will be exited soon" , e); hitDown = true ; LockSupport.unpark(exitThread); } } }
创建checkpoint 创建checkpoint将内存中的数据放到临时存储CheckTmpStore中去。CheckTmpStore的具体做了什么。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 private void createCheckpoint () try { Map<WrappedByteArray, WrappedByteArray> batch = new HashMap<>(); for (Chainbase db : dbs) { Snapshot head = db.getHead(); if (Snapshot.isRoot(head)) { return ; } String dbName = db.getDbName(); Snapshot next = head.getRoot(); for (int i = 0 ; i < flushCount; ++i) { next = next.getNext(); SnapshotImpl snapshot = (SnapshotImpl) next; DB<Key, Value> keyValueDB = snapshot.getDb(); for (Map.Entry<Key, Value> e : keyValueDB) { Key k = e.getKey(); Value v = e.getValue(); batch.put(WrappedByteArray.of(Bytes.concat(simpleEncode(dbName), k.getBytes())), WrappedByteArray.of(v.encode())); } } } checkTmpStore.getDbSource().updateByBatch(batch.entrySet().stream() .map(e -> Maps.immutableEntry(e.getKey().getBytes(), e.getValue().getBytes())) .collect(HashMap::new , (m, k) -> m.put(k.getKey(), k.getValue()), HashMap::putAll), WriteOptionsWrapper.getInstance().sync(CommonParameter .getInstance().getStorage().isDbSync())); } catch ( Exception e) { throw new TronDBException(e); } }
创建checkpoint就是这么点事,那么问题来了
创建checkpoint过程中如果程序挂了,数据会不会有问题? 如查程序挂了,数据没有写入到数据库中,只会丢失内存部分的数据库。原始数据没有受到影响,缺失的部分从其它节点同步后获得。
数据丢失了怎么办? checkpoint创建成功后,如果服务挂了,重启后会先检查checkpoint中的数据,如果存在就加载到内存当中。所以这个机制本身就是用来防止写库时 丢失内存数据的。
机器宕机了怎么办? 宕机数据有可能会丢失!!!createCheckpoint进行调用checkTmpStore写到一半机器宕机了,那数据有可能只有了一半,就会出现脏数据。这样的话,下次服务启动后,数据有可能对不上,服务就会一直处理异常状态。
checkTmpStore 作用:存储内存快照(Snapshot)数据。
检查checkpoint 在java-tron服务启动时,检查checkpoint是否有数据,如果有数据,则将数据加载入内存当中。
启动流程:
1 2 3 Manager.init() |---revokingStore.check(); |---SnapshotManager.check()
SnapshotManager.check() 中check的就是checkpoint的状态。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 @Override public void check () for (Chainbase db : dbs) { if (!Snapshot.isRoot(db.getHead())) { throw new IllegalStateException("first check." ); } } if (!checkTmpStore.getDbSource().allKeys().isEmpty()) { Map<String, Chainbase> dbMap = dbs.stream() .map(db -> Maps.immutableEntry(db.getDbName(), db)) .collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue)); advance(); for (Map.Entry<byte [], byte []> e : checkTmpStore.getDbSource()) { byte [] key = e.getKey(); byte [] value = e.getValue(); String db = simpleDecode(key); if (dbMap.get(db) == null ) { continue ; } byte [] realKey = Arrays.copyOfRange(key, db.getBytes().length + 4 , key.length); byte [] realValue = value.length == 1 ? null : Arrays.copyOfRange(value, 1 , value.length); if (realValue != null ) { dbMap.get(db).getHead().put(realKey, realValue); } else { dbMap.get(db).getHead().remove(realKey); } } dbs.forEach(db -> db.getHead().getRoot().merge(db.getHead())); retreat(); } unChecked = false ; }
总结 checkPoint机制可以有效的防止服务挂掉时保存内存中的数据,但是宕机的场景的话确实没有办法,包括像RocketMQ号称高可用也没有办法解决宕机队列数据丢失的问题。