关于Reactor模型
核心思想:分治
看了一些 Reactor 相关的文章和资料,列举的一些 Reactor 模型的优点,包括极客时间的文章也有讲过在架构中的Reactor中的优点和缺点。
但是如果不使用 Reactor 模型的一般方式是什么样子的?会有什么问题?
思想:分而治之+事件驱动
1)分而治之
一个连接里完整的网络处理过程一般分为accept、read、decode、process、encode、send这几步。
Reactor模式将每个步骤映射为一个Task,服务端线程执行的最小逻辑单元不再是一次完整的网络请求,而是Task,且采用非阻塞方式执行。
2)事件驱动
每个Task对应特定网络事件。当Task准备就绪时,Reactor收到对应的网络事件通知,并将Task分发给绑定了对应网络事件的Handler执行。
3)几个角色
reactor:负责绑定管理事件和处理接口;
selector:负责监听响应事件,将事件分发给绑定了该事件的Handler处理;
Handler:事件处理器,绑定了某类事件,负责执行对应事件的Task对事件进行处理;
Acceptor:Handler的一种,绑定了connect事件。当客户端发起connect请求时,Reactor会将accept事件分发给Acceptor处理。
Reactor是什么?
- 事件驱动
- 可以处理一个或多个输入源
- 通过多路复用将请求的事件分发给对应的处理器处理
Reactor模式首先是事件驱动的,有一个或多个并发输入源,有一个Service Handler,有多个Request Handlers;这个Service Handler会同步的将输入的请求(Event)多路复用的分发给相应的Request Handler。
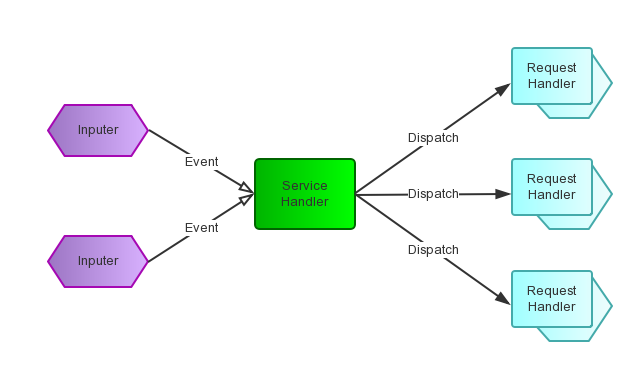
从结构上,这有点类似生产者消费者模式,即有一个或多个生产者将事件放入一个Queue中,而一个或多个消费者主动的从这个Queue中Poll事件来处理;而Reactor模式则并没有Queue来做缓冲,每当一个Event输入到Service Handler之后,该Service Handler会主动的根据不同的Event类型将其分发给对应的Request Handler来处理。
Reactor模式结构
在解决了什么是Reactor模式后,我们来看看Reactor模式是由什么模块构成。
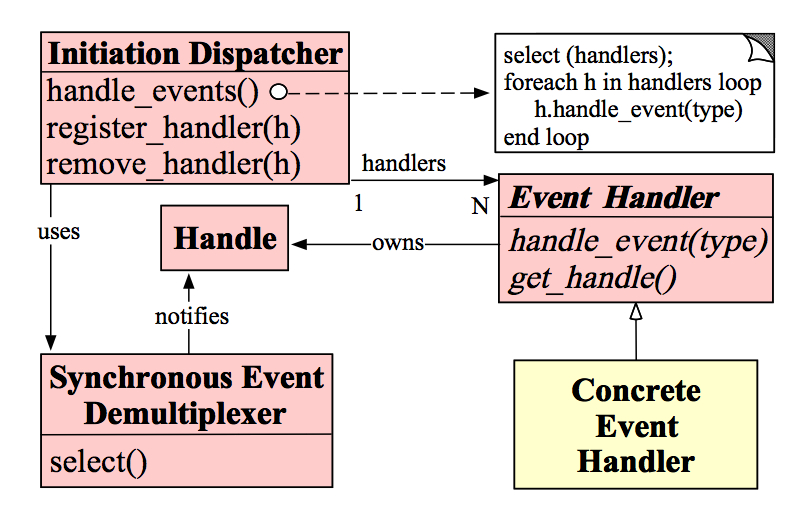
- Handle:即操作系统中的句柄,是对资源在操作系统层面上的一种抽象,它可以是打开的文件、一个连接(Socket)、Timer等。由于Reactor模式一般使用在网络编程中,因而这里一般指Socket Handle,即一个网络连接(Connection,在Java NIO中的Channel)。这个Channel注册到Synchronous Event Demultiplexer中,以监听Handle中发生的事件,对ServerSocketChannnel可以是CONNECT事件,对SocketChannel可以是READ、WRITE、CLOSE事件等。
- Synchronous Event Demultiplexer:阻塞等待一系列的Handle中的事件到来,如果阻塞等待返回,即表示在返回的Handle中可以不阻塞的执行返回的事件类型。这个模块一般使用操作系统的select来实现。在Java NIO中用Selector来封装,当Selector.select()返回时,可以调用Selector的selectedKeys()方法获取Set
,一个SelectionKey表达一个有事件发生的Channel以及该Channel上的事件类型。上图的Synchronous Event Demultiplexer ---notifies--> Handle”的流程如果是对的,那内部实现应该是select()方法在事件到来后会先设置Handle的状态,然后返回。不了解内部实现机制,因而保留原图。 - Initiation Dispatcher:用于管理Event Handler,即EventHandler的容器,用以注册、移除EventHandler等;另外,它还作为Reactor模式的入口调用Synchronous Event Demultiplexer的select方法以阻塞等待事件返回,当阻塞等待返回时,根据事件发生的Handle将其分发给对应的Event Handler处理,即回调EventHandler中的handle_event()方法。
- Event Handler:定义事件处理方法:handle_event(),以供InitiationDispatcher回调使用。
- Concrete Event Handler:事件EventHandler接口,实现特定事件处理逻辑。
为什么需要 Reactor 模型
最最原始的网络编程思路就是服务器用一个while循环,不断监听端口是否有新的套接字连接,如果有,那么就调用一个处理函数处理,类似:
1 | while(true){ |
这种方法的最大问题是无法并发,效率太低,如果当前的请求没有处理完,那么后面的请求只能被阻塞,服务器的吞吐量太低。
之后,想到了使用多线程,也就是很经典的connection per thread,每一个连接用一个线程处理,类似:
1 | while(true){ |
tomcat服务器的早期版本确实是这样实现的。多线程的方式确实一定程度上极大地提高了服务器的吞吐量,因为之前的请求在read阻塞以后,不会影响到后续的请求,因为他们在不同的线程中。这也是为什么通常会讲“一个线程只能对应一个socket”的原因。最开始对这句话很不理解,线程中创建多个socket不行吗?语法上确实可以,但是实际上没有用,每一个socket都是阻塞的,所以在一个线程里只能处理一个socket,就算accept了多个也没用,前一个socket被阻塞了,后面的是无法被执行到的。
缺点在于资源要求太高,系统中创建线程是需要比较高的系统资源的,如果连接数太高,系统无法承受,而且,线程的反复创建-销毁也需要代价。
线程池本身可以缓解线程创建-销毁的代价,这样优化确实会好很多,不过还是存在一些问题的,就是线程的粒度太大。每一个线程把一次交互的事情全部做了,包括读取和返回,甚至连接,表面上似乎连接不在线程里,但是如果线程不够,有了新的连接,也无法得到处理,所以,目前的方案线程里可以看成要做三件事,连接,读取和写入。
线程同步的粒度太大了,限制了吞吐量。应该把一次连接的操作分为更细的粒度或者过程,这些更细的粒度是更小的线程。整个线程池的数目会翻倍,但是线程更简单,任务更加单一。这其实就是Reactor出现的原因,在Reactor中,这些被拆分的小线程或者子过程对应的是handler,每一种handler会出处理一种event。这里会有一个全局的管理者selector,我们需要把channel注册感兴趣的事件,那么这个selector就会不断在channel上检测是否有该类型的事件发生,如果没有,那么主线程就会被阻塞,否则就会调用相应的事件处理函数即handler来处理。典型的事件有连接,读取和写入,当然我们就需要为这些事件分别提供处理器,每一个处理器可以采用线程的方式实现。一个连接来了,显示被读取线程或者handler处理了,然后再执行写入,那么之前的读取就可以被后面的请求复用,吞吐量就提高了。