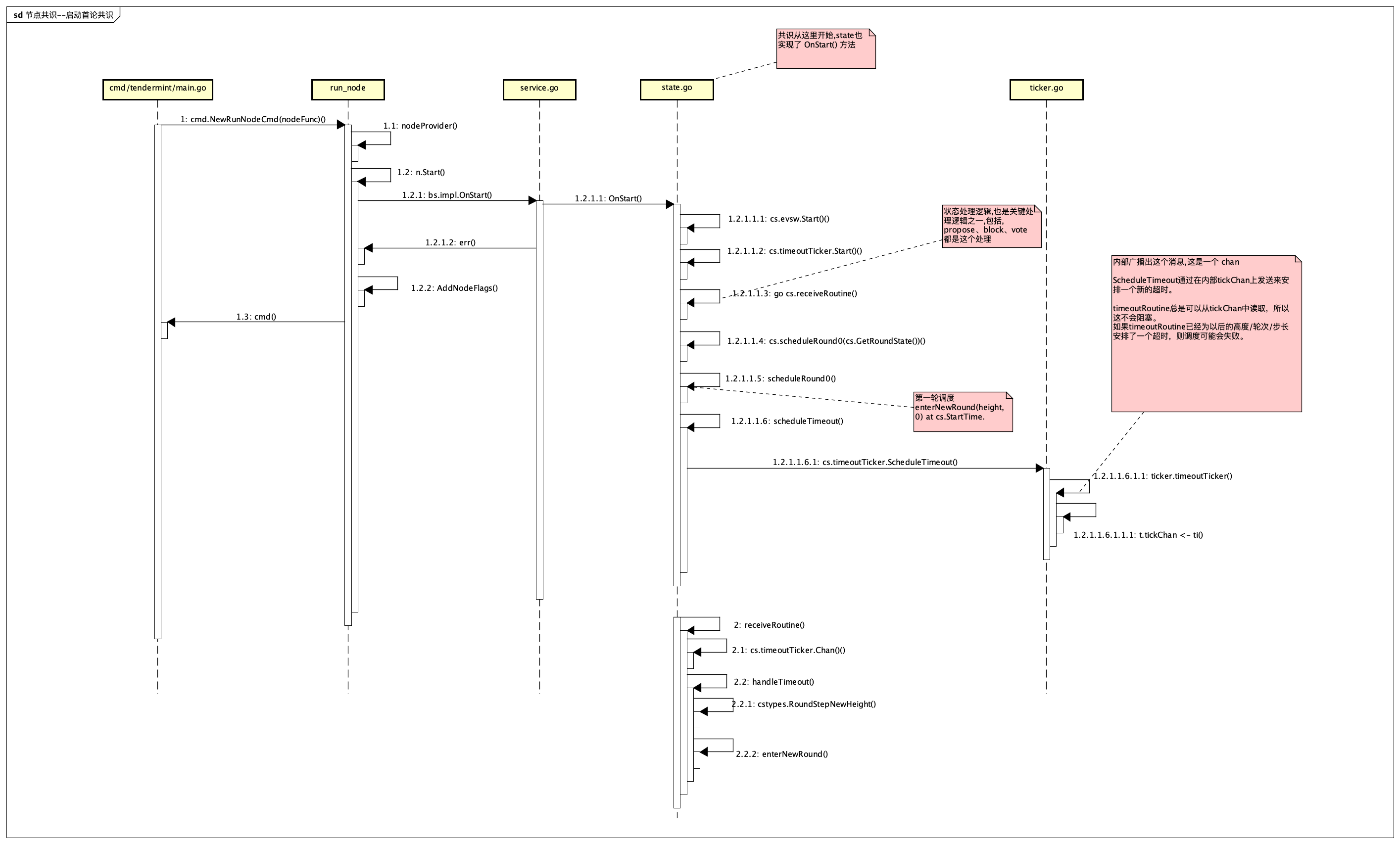
// OnStart loads the latest state via the WAL, and starts the timeout and // receive routines. // OnStart通过WAL加载最新状态,并启动超时和接收程序。 func(cs *State)OnStart()error { // We may set the WAL in testing before calling Start, so only OpenWAL if its // still the nilWAL. // 在测试中,我们可能会在调用Start之前设置WAL,所以只有在其仍然是nilWAL的情况下才会打开WAL。 if _, ok := cs.wal.(nilWAL); ok { if err := cs.loadWalFile(); err != nil { return err } }
// We may have lost some votes if the process crashed reload from consensus // log to catchup. // 如果从共识日志到追赶的过程中崩溃重新加载,我们可能会失去一些票数。 if cs.doWALCatchup { repairAttempted := false
LOOP: for { err := cs.catchupReplay(cs.Height) switch { case err == nil: break LOOP
case !IsDataCorruptionError(err): cs.Logger.Error("error on catchup replay; proceeding to start state anyway", "err", err) break LOOP
case repairAttempted: return err }
cs.Logger.Error("the WAL file is corrupted; attempting repair", "err", err)
// 1) prep work if err := cs.wal.Stop(); err != nil { return err }
// we need the timeoutRoutine for replay so // we don't block on the tick chan. // NOTE: we will get a build up of garbage go routines // firing on the tockChan until the receiveRoutine is started // to deal with them (by that point, at most one will be valid) // 我们需要重放的timeoutRoutine,这样我们就不会在tick chan上阻塞。 // 注意:我们将得到大量的垃圾程序 // 直到receiveRoutine开始处理它们(到那时,最多只有一个是有效的)来处理它们(到那时,最多只有一个是有效的)。 if err := cs.timeoutTicker.Start(); err != nil { return err }
// now start the receiveRoutine // 启动接收程序 go cs.receiveRoutine(0)
// schedule the first round! // use GetRoundState so we don't race the receiveRoutine for access // 安排第一轮! // 使用GetRoundState,这样我们就不会和receiveRoutine争夺访问权了。 cs.scheduleRound0(cs.GetRoundState())
// ScheduleTimeout schedules a new timeout by sending on the internal tickChan. // The timeoutRoutine is always available to read from tickChan, so this won't block. // The scheduling may fail if the timeoutRoutine has already scheduled a timeout for a later height/round/step. // ScheduleTimeout通过在内部tickChan上发送来安排一个新的超时。 // timeoutRoutine总是可以从tickChan中读取,所以这不会阻塞。 // 如果timeoutRoutine已经为以后的高度/轮次/步长安排了一个超时,则调度可能会失败。 func(t *timeoutTicker)ScheduleTimeout(ti timeoutInfo) { t.tickChan <- ti }
//----------------------------------------- // the main go routines
// receiveRoutine handles messages which may cause state transitions. // it's argument (n) is the number of messages to process before exiting - use 0 to run forever // It keeps the RoundState and is the only thing that updates it. // Updates (state transitions) happen on timeouts, complete proposals, and 2/3 majorities. // State must be locked before any internal state is updated. // receiveRoutine处理可能导致状态转换的消息。 // 它的参数(n)是退出前要处理的消息的数量--用0表示永远运行。 // 它保持RoundState,并且是唯一能更新它的东西。 // 更新(状态转换)发生在超时、完整提案和2/3多数的情况下。 // 在任何内部状态被更新之前,状态必须被锁定。 func(cs *State)receiveRoutine(maxSteps int) { ... // 拿到当前链状态 rs := cs.RoundState
//监听内部队列消息 case mi = <-cs.internalMsgQueue: err := cs.wal.WriteSync(mi) // NOTE: fsync if err != nil { panic(fmt.Sprintf( "failed to write %v msg to consensus WAL due to %v; check your file system and restart the node", mi, err, )) }
if now := tmtime.Now(); cs.StartTime.After(now) { logger.Debug("need to set a buffer and log message here for sanity", "start_time", cs.StartTime, "now", now) }
logger.Debug("entering new round", "current", fmt.Sprintf("%v/%v/%v", cs.Height, cs.Round, cs.Step))
// Setup new round // we don't fire newStep for this step, // but we fire an event, so update the round step first // 只是 set 值,并没有接口调用 cs.updateRoundStep(round, cstypes.RoundStepNewRound) ...//省略部分代码 cs.Votes.SetRound(tmmath.SafeAddInt32(round, 1)) // also track next round (round+1) to allow round-skipping cs.TriggeredTimeoutPrecommit = false
// 发布事件?? if err := cs.eventBus.PublishEventNewRound(cs.NewRoundEvent()); err != nil { cs.Logger.Error("failed publishing new round", "err", err) }
cs.metrics.Rounds.Set(float64(round))
// Wait for txs to be available in the mempool // before we enterPropose in round 0. If the last block changed the app hash, // we may need an empty "proof" block, and enterPropose immediately. // 进入 round0 之前,等待mempool中的txs可用。 // 如果最后一个区块改变了应用程序的哈希值,我们可能需要一个空的 "证明 "区块,并立即输入Propose。 waitForTxs := cs.config.WaitForTxs() && round == 0 && !cs.needProofBlock(height) if waitForTxs { if cs.config.CreateEmptyBlocksInterval > 0 { // 构建空块证明,进入下一个阶段 cs.scheduleTimeout(cs.config.CreateEmptyBlocksInterval, height, round, cstypes.RoundStepNewRound) } } else { // 进入 propose 阶段 cs.enterPropose(height, round) } }